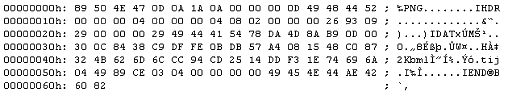Este es un artículo que escribí hace años para una asignatura de la universidad, y más tarde colgué de una web que ya no existe. así que aprovecho para rescatarlo.
Introducción.
El formato PNG (Portable Network Graphics) es un formato gráfico que usa compresión sin pérdidas (loseless compression). Es el formato actualmente recomendado por la organización W3C (World Wide Web Consortium) para imágenes sin pérdida de calidad.
Se trata de un sustituto al formato GIF (CompuServe's Graphics Interchange Format), que al contrario que éste, está libre de patentes, con lo que puede usarse libremente. Usa una compresión mejor, gracias al uso de las técnicas LZ77 y Huffman y a los filtros sin pérdida de que dispone. Permite imágenes en escala de grises, paleta y truecolor, con y sin canal alfa, permitiendo 256 niveles de transparencias por pixel, a profundidades de bits de 1 a 16 bits por componente (hasta 48 bits por pixel).
Está diseñado para ser utilizado en el Web, con lo que permite su visualización progresiva (es streamable). En especial se beneficia en este apartado del método de entrelazado Adam7, que permite una mejor apreciación de la imagen mucho antes que en el entrelazado del formato GIF.
También tiene control de errores gracias a los códigos CRC-32 y Adler-32 que almacena.
Puede almacenar el gamma y datos de cromaticidad para mejorar la visualización en distintas plataformas (Mac, PC,…), con lo que obtenemos una completa independencia del hardware, al contrario que otros formatos en los que dependiendo de la máquina puede verse más claro o más oscura la imagen, etc.
Especificación del formato.
El formato PNG está compuesto por una cabecera seguido por una serie de chunks o trozos. Cada uno de estos chunks está compuesto a su vez por un entero de 4 bytes que indica la longitud en bytes del chunk, un identificador del chunk de también 4 bytes, el cuerpo del chunk y a continuación un CRC para comprobar la existencia de errores.
Esta estructura permite extender el formato sin afectar la compatibilidad, ya que los chunks principales se mantienen fijos, mientras que son los opcionales o ancillary chunks los que posibilitan las extensiones al formato. En caso de que un descompresor no reconozca o no tenga implementados alguno de los chunks opcionales, basta con saltar el chunk y seguir con el resto de chunks del fichero.
Los chunks principales son:
IHDR Image header. Es el primero que debe aparecer en la imagen. Almacena información tal como el ancho y alto de la imagen, su tipo de color, si está entrelazada, etc.
PLTE Palette. Si la imagen usa color indexado, debe aparecer este chunk donde indica la paleta a utilizar.
IDAT Image data. Aqui se almacena el grueso de la imagen, comprimido usando el algoritmo Deflate (RFC 1951).
IEND Image trailer. Indica el final del stream.
Además también encontramos otros chunks opcionales, como:
tRNS Transparency
gAMA Image gamma
cHRM Primary chromaticities
sRGB Standard RGB color space
iCCP Embedded ICC profile
tEXt Textual data
zTXt Compressed textual data
iTXt International textual data
bKGD Background color
pHYs Physical pixel dimensions
sBIT Significant bits
sPLT Suggested palette
hIST Palette histogram
tIME Image last-modification time
Estos chunks por ser opcionales pueden no estar en un fichero, además, un descodificador puede ignorarlos sin que esto suponga un grave problema.
Filtros.
El formato PNG permite filtrar la imagen antes de pasarla a la etapa de compresión para así obtener mejores resultados. Se puede elegir el filtro que se va a usar en cada scanline, de modo que optimicemos en la medida de lo posible el tamaño final de la imagen comprimida. Dispone de cinco tipos básicos de filtrado sin pérdida de información:
Tipo 0: None. La scanline se transmite sin modificar.
Tipo 1: Sub. Se computa la diferencia entre la componente actual y la misma componente del pixel anterior.
Sub(x) = Raw(x) - Raw(x-bpp)
Tipo 2: Up. Se computa la diferencia entre la componente actual y la misma componente del mismo pixel de la anterior scanline.
Up(x) = Raw(x) - Prior(x)
Tipo 3: Average. Se calcula la media entre el valor de la misma componente del pixel anterior y la misma componente del mismo pixel de la anterior scanline, redondeando siempre hacia abajo. El valor que almacenamos es la diferencia respecto a este valor.
Average(x) = Raw(x) - floor((Raw(x-bpp)+Prior(x))/2)
Tipo 4: Paeth. Este filtro calcula una función matemática que depende del valor de la misma componente del pixel superior, del pixel situado a la izquierda y del arriba a la izquierda. Una vez calculado este valor usa como predicción el pixel de estos tres que más se acerque al valor calculado.
Paeth(x) = Raw(x) - PaethPredictor(Raw(x-bpp), Prior(x), Prior(x-bpp))
Para ampliar información puede consultarse la especificación del formato PNG, en la RFC 2083.
Método de compresión utilizado: Deflate/Inflate.
El método de compresión usado en el formato PNG es un derivado del LZ77, usado en zip, gzip, pkzip, etc.
Los datos se almacenan en el formato zlib (especificado en la RFC 1950). Un bloque zlib está compuesto por:
2 bytes de cabecera, donde entre otras cosas se guarda el método de compresión utilizado, en el caso del formato PNG, al igual que sucede con el gzip, sólo es válido el método 8 (Deflate).
Los datos comprimidos.
Un código de detección de errores Adler-32.
El método de compresión Deflate está definido en la RFC 1951.
Una secuencia de datos comprimidos está dividido en una serie de bloques. Cada bloque es comprimido usando una combinación de LZ77 y códigos de Huffman. Los árboles de Huffman para cada bloques son independientes, mientras que el algoritmo LZ77 podría referenciar una cadena que se encuentre en un bloque anterior.
Las lecturas se realizan bit a bit, en orden ascendente dentro de cada byte, que se lee también ascendentemente. En los códigos de Huffman el primer bit leido es el de mayor peso, y luego continúa descendentemente. Ej:
byte actual: 11011101 sería leido como:
10111 (si se trata de un código Huffman de 5 bits)
El resto de lecturas se interpretan en orden inverso, es decir, el primer bit que
leemos es el de menor peso. Ej:
byte actual: 11011101 sería leido como:
11011 (si se trata de un código Huffman de 5 bits)
Uso de códigos de Huffman en Deflate.
Vamos a definir el uso de los códigos de Huffman para el algoritmo Deflate. Dados dos códigos de igual longitud, es anterior el menor en orden lexicográfico. Así, en el código:
A 10
B 0
C 110
D 111
el primer elemento sería el B, seguido del A, C y D.
Teniendo en cuenta este orden, va a ser posible reconstruir los códigos de Huffman dadas las longitudes respectivas de cada código. Así, el código anterior quedaría representado por la secuencia (2, 1, 3, 3). El algoritmo para reconstruir los códigos de Huffman a partir de sus longitudes de código es el siguiente:
1) Contar el número de códigos para cada longitud. Sea bl_count[N] el número de códigos de longitud N, N >= 1.
2) Encuentra el valor numérico del código más pequeño para cada longitud de código:
code = 0;
bl_count[0] = 0;
for (bits = 1; bits <= MAX_BITS; bits++) {
code = (code + bl_count[bits-1]) << 1;
next_code[bits] = code;
}
3) Asigna valores numéricos a todos los códigos, usando valores consecutivos para todos los códigos de la misma longitud con los valores base determinados en el punto 2. A los códigos que no se usan (que tienen una longitud de 0 bits) no se les debe asignar un valor.
for (n = 0; n <= max_code; n++) {
len = tree[n].Len;
if (len != 0) {
tree[n].Code = next_code[len];
next_code[len]++;
}
}
Formato de bloque.
En primer lugar encontramos la cabecera del bloque. El primer bit indica si se trata del último bloque del campo zlib, mientras que los dos bits que hay a continuación indican el tipo de compresión que usa el bloque, donde:
00 --> Sin compresión
01 --> Comprimido con códigos de Huffman estáticos.
10 --> Comprimido con códigos de Huffman dinámicos.
11 --> Reservado (error).
Bloques sin compresión.
Tienen una sub-cabecera de 4 bytes, donde:
LEN (2 bytes): indica el número de bytes de datos en el campo.
NLEN (2 bytes): complemento a 1 de LEN.
Bloques con compresión.
Estos bloques se definen por secuencias de literales y pares <longitud, distancia hacia atrás>. Esto se representa mediante un alfabeto para literales/longitudes y otro para distancias. El alfabeto de literales/longitudes se define como:
0-255 literales
256 fin de bloque
257-285 códigos de longitud (en conjunción con bits adicionales)
El alfabeto de longitudes con los bits adicionales para cada elemento se muestran en la siguiente tabla:
| Código | Bits Extra | Longitud | Código | Bits Extra | Longitud | Código | Bits Extra | Longitud |
| 257 | 0 | 3 | 267 | 1 | 15,16 | 277 | 4 | 67-82 |
| 258 | 0 | 4 | 268 | 1 | 17,18 | 278 | 4 | 83-98 |
| 259 | 0 | 5 | 269 | 2 | 19-22 | 279 | 4 | 99-114 |
| 260 | 0 | 6 | 270 | 2 | 23-26 | 280 | 4 | 115-130 |
| 261 | 0 | 7 | 271 | 2 | 27-30 | 281 | 5 | 131-162 |
| 262 | 0 | 8 | 272 | 2 | 31-34 | 282 | 5 | 163-194 |
| 263 | 0 | 9 | 273 | 3 | 35-42 | 283 | 5 | 195-226 |
| 264 | 0 | 10 | 274 | 3 | 43-50 | 284 | 5 | 227-257 |
| 265 | 1 | 11,12 | 275 | 3 | 51-58 | 285 | 0 | 258 |
| 266 | 1 | 13,14 | 276 | 3 | 59-66 |
|
|
|
Recordemos que en las lecturas de los códigos de Huffman leemos el bit más significativo en primer lugar, mientras que en los demás símbolos, incluidos bits adicionales, leemos primero el bit menos significativo.
A continuación podemos ver el alfabeto utilizado para distancias:
| Código | Bits Extra | Distancia | Código | Bits Extra | Distancia | Código | Bits Extra | Distancia |
| 0 | 0 | 1 | 10 | 4 | 33-48 | 20 | 9 | 1025-1536 |
| 1 | 0 | 2 | 11 | 4 | 49-64 | 21 | 9 | 1537-2048 |
| 2 | 0 | 3 | 12 | 5 | 65-96 | 22 | 10 | 2049-3072 |
| 3 | 0 | 4 | 13 | 5 | 97-128 | 23 | 10 | 3073-4096 |
| 4 | 1 | 4,6 | 14 | 6 | 129-192 | 24 | 11 | 4097-6144 |
| 5 | 1 | 7,8 | 15 | 6 | 193-256 | 25 | 11 | 6145-8192 |
| 6 | 2 | 9-12 | 16 | 7 | 257-384 | 26 | 12 | 8193-12288 |
| 7 | 2 | 13-16 | 17 | 7 | 385-512 | 27 | 12 | 12289-16384 |
| 8 | 3 | 17-24 | 18 | 8 | 513-768 | 28 | 13 | 13685-24576 |
| 9 | 3 | 25-32 | 19 | 8 | 769-1024 | 29 | 13 | 24577-32768 |
Tenemos que tener en cuenta que una distancia puede cruzar el límite bloque para acceder a datos que se encontraban en un bloque anterior.
El proceso de descompresión se limita a leer un código literal/distancia. Si se trata del 256, terminamos el bloque. Si es menor que este número tenemos un literal sin comprimir. Si es mayor tenemos un par <longitud, distancia>, con lo que tenemos que leer la longitud y sus códigos adicionales si fuera el caso, y la distancia con sus bits adicionales asociados. Una vez tenemos un par <longitud, distancia> debemos repetir lo que encontremos a "distancia" bytes de distancia "longitud" bytes, pudiendo ser "longitud" mayor que "distancia", caso en el que deberíamos repetir de nuevo el contenido que hay a "distancia" bytes.
Compresión con códigos Huffman estáticos.
Los códigos de Huffman que usa son fijos y no vienen representados en los datos. Sus longitudes de código son:
Valor Bits Códigos
0 --> 143 8 00110000 - 10111111
144 --> 255 9 110010000 - 111111111
256 --> 279 7 0000000 - 0010111
280 --> 287 8 11000000 - 11000111
En la tabla anterior los códigos en sí no son necesarios, puesto que pueden extraerse de las longitudes de código usando el algoritmo anteriormente expuesto.
Las distancias se representan mediante códigos de 5 bits, por lo tanto al no ser códigos de Huffman leemos primero el bit menos significativo. Además pueden haber bits adicionales (ver tabla distancias).
Compresión con códigos Huffman dinámicos.
En el caso de los códigos Huffman dinámicos éstos se almacenan antes de los datos comprimidos. Tanto el código de literales/longitudes como el código de distancias se almacena por sus longitudes de código. Estas longitudes de código a su vez están comprimidas usando otro código Huffman, que también se almacena por sus longitudes de código. Veamos detalladamente cual es la organización.
Los 5 primeros bits (HLIT-257) indican el número de códigos literales/longitud (257-286). Los 5 bits siguientes (HDIST-1) indican el número de códigos de distancia (1-32). Los 4 bits siguientes (HCLEN-4) indican el número de códigos de longitud de código (4-19).
Ahora leeremos HCLEN números de 3 bits, que indican las longitudes de código para construir el alfabeto de longitudes de código. Una longitud de 0 indica que ese código no se da en bloque. Los elementos restantes hay que suponerlos 0. Sin embargo, estos números que hemos leído no están ordenados, sino que para conseguir una mayor compresión están almacenados en otro orden, en concreto en el orden: 16, 17, 18, 0, 8, 7, 9, 6, 10, 5, 11, 4, 12, 3, 13, 2, 14, 1, 15. Por
lo tanto tendremos que hacer el correspondiente intercambio. Una vez hayamos leído y colocado en su sitio las longitudes de código estaremos en disposición de generar los códigos de Huffman con el algoritmo previamente mencionado. Este código de Huffman recién generado nos servirá para leer los códigos de literal/longitud y distancia.
Ahora debemos ir leyendo códigos de Huffman correspondientes al alfabeto recién generado y usando la siguiente correspondencia generaremos HLIT longitudes de código de códigos de literal/longitud:
0 - 15: Representa longitudes de código de 0 - 15
16: Copia la longitud de código anterior 3 - 6 veces.
Los 2 bits siguientes indican las veces que se repite (0 = 3, ... , 3 = 6).
17: Repite una longitud de código de 0 por 3 - 10 veces.
(3 bits extra)
18: Repite una longitud de código de 0 por 11 - 138 veces.
(7 bits extra)
Y después estas longitudes de código, encontraremos HDIST longitudes de código codificadas con el mismo alfabeto. Hay que tener en cuenta que las repeticiones de longitudes de código pueden cruzar el límite HLIT-HDIST.
Una vez tenemos las longitudes de código tanto del alfabeto literal/longitud como distancia podemos generar los correspondientes códigos de Huffman, cuya traducción se hace igual que en el caso de códigos Huffman estáticos, con los mismos bits extra, etc, con lo que ya en conocimiento de los códigos de Huffman ya estamos en disposición de descomprimir el cuerpo del bloque, siguiendo el procedimiento ya señalado.
Un ejemplo práctico.
Para aclarar las ideas vamos a descomprimir un fichero. Observamos en primer lugar que efectivamente se trata de un fichero PNG, y como tal comienza por los bytes "89 50 4e 47 0d 0a 1a 0a".
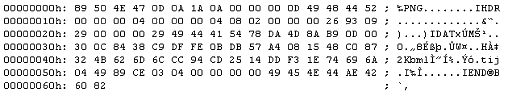
Empezamos con el procesamiento de los chunks.
CHUNK: IHDR LONGITUD: 13
CONTENIDO DEL CAMPO DE DATOS:
00 00 00 04 00 00 00 04 08 02 00 00 00
CRC32: 26 93 09 29
Leemos la longitud del chunk "00 00 00 0D" en MSB que sería 13. Se trata del chunk IHDR. El campo de datos contiene los bytes "00 00 00 04 00 00 00 04 08 02 00 00 00". De aquí podemos extraer que se trata de una imagen de 4x4 pixels, 8 bits por componente, color RGB, no entrelazado, y que usa la compresión 0 y el filtro 0 (los únicos definidos en la especificación del PNG). A continuación encontramos el Crc-32 del campo de datos: "26 93 09 29".
CHUNK: IDAT LONGITUD: 41
CONTENIDO DEL CAMPO DE DATOS:
78 DA 4D 8A B9 0D 00 30 0C 84 38 C9 DF FE 0B DB 57 A4 08 15 48 C0 87 32 4B 62 6D 6C CC 94 CD 25 14 DD F3 1E 74 69 6A 04 49
CRC32: 89 CE 03 04
Como se trata de un campo IDAT contiene los datos comprimidos que formarán la imagen. Así pues, dado que estamos bajo el método de compresión 0, el campo de datos se corresponde con uno o más bloques zlib.
En último lugar en el fichero encontramos un chunk que indica el final del fichero:
CHUNK: IEND LONGITUD: 0
CONTENIDO DEL CAMPO DE DATOS:
CRC32: AE 42 60 82
Vamos a descomprimir el bloque zlib contenido en el campo IDAT:
CABECERA: 78 DA
CUERPO: 4D 8A B9 0D 00 30 0C 84 38 C9 DF FE 0B DB 57 A4 08 15
48 C0 87 32 4B 62 6D 6C CC 94 CD 25 14 DD F3 1E 74
ADLER-32: 69 6A 04 49
Si nos fijamos en los campos de la cabecera que nos interesan, tenemos que observar que en los 4 bits de menor peso del primer byte se indica el uso del método de compresión 8 (inflate/deflate), que es el único válido en los PNG al igual que en los GZIP. En el bit 5 del segundo byte indica que usamos el diccionario predeterminado, lo cual también es necesario en el formato PNG. Al final encontramos un código de detección de errores ADLER-32 ("69 6A 04 49").
A partir de ahora vamos a necesitar los datos en forma de bits:
01001101 10001010 10111001 00001101 00000000 00110000 00001100 10000100 00111000 11001001 11011111 11111110 00001011 11011011 01010111 10100100 00001000 00010101 01001000 11000000 10000111 00110010 01001011 01100010 01101101 01101100 11001100 10010100 11001101 00100101 00010100 11011101 11110011 00011110 01110100
Leemos el primer bit del primer byte (1). Esto indica que este bloque es el último. Leemos
los dos bits siguientes (10), que indican compresión usando códigos dinámicos Huffman. Ahora procedemos a leer HLIT = (01001 = 9) + 257 = 266, HDIST = (01010 = 10) + 1 = 11 y HCEN = (1100 = 12) + 4 = 16.
Leemos HCEN (16) números de 3 bits: 100, 011, 011, 011, 000, 000, 000, 000, 000, 011, 000, 011, 000, 100, 000, 010 y los colocamos en su sitio dado que en el fichero se encuentran desordenados:
{4, 3, 3, 3, 0, 0, 0, 0, 0, 3, 0, 3, 0, 4, 0, 2 } à
{3, 0, 2, 4, 3, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 3, 3}
Vamos ahora a construir el código de longitudes de código. Contamos el número de elementos que hay para cada longitud de código:
bl_count = {0, 0, 1, 5, 2}
A partir de aquí y con el algoritmo ya citado calculamos el menor valor para cada longitud de código:
next_code = {0, 0, 0, 2, 14}
Así pues el código generado sería:
{010, -, 00, 1110, 011, 100, -, -, -, -, -, -, -, -, -, -, 1111, 101, 110}
Una vez conocemos este alfabeto, estamos en disposición de descomprimir las longitudes
de código del alfabeto de literales/longitudes y distancias:
00 (2:literal), 1110 (3), 010 (0), 010 (0), 011 (4),
1111 : 16 - leemos 2 bits extra: 01 = 1 + 3 = 4 (4 4"s),
110 : 18 - leemos 7 bits extra: 1111111 = 127 + 11 = 138 (138 veces 0),
110 : 18 - 1100001 = 97 + 11 = 108 (108 veces 0),
011 (4), 011 (4), 1110 (3),
101 : 17 - leemos 3 bits extra: 000 = 0 + 3 = 3 (3 veces 0),
100 (5),
101 : 17 - leemos 3 bits extra: 000 = 0 + 3 = 3 (3 veces 0),
100 (5)
Con lo que las longitudes quedarán así:
{2, 3, 0, 0, 4, 4, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 4, 3, 0, 0, 0, 5, 0, 0, 0, 5}
Y el código de literales/longitudes sería:
{00, 010, -, -, 1000, 1001, 1010, 1011, 1100, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, -, 1101, 1110, 011, -, -, -, 11110, -, -, -, 11111}
De igual forma leemos las longitudes de código para generar el código de distancias:
00 (2),
101 : 17 - leemos 3 bits extra: 010 = 2 + 3 = 5 (5 veces 0)
00 (2), 00 (2), 010 (0), 010 (0), 00 (2)
Las longitudes serían:
{2, 0, 0, 0, 0, 0, 2, 2, 0, 0, 2}
Y el código generado:
{00, -, -, -, -, -, 01, 10, -, -, 11}
Ahora ya sabemos los dos alfabetos necesarios para descomprimir los datos de la
imagen podemos realizar este paso:
0, 0, <265 (11+0), 0 (1)>, 1, 5, 5, 6, 1, 1, 0, 255, <257 (3), 6 (9+1)>, 0, 255, 4, 8, 8, 6, <257 (3), 6 (9+1)>, <257 (3), 7 (13+1)>, 1, 0, 1, 4, 7, 7, 8, <261 (7), 10 (33+3)>, 0, 1, 256
Al llegar al código 256 quiere decir que el bloque actual ha terminado. Como el bloque actual recordemos que era el último, ya tenemos todos los datos descomprimidos. Ahora sólo resta desentrelazar la imagen (si procede) y aplicar la inversa de los filtros. Según la solución a la que hemos llegado antes, los datos crudos serían (en hexadecimal):
0 0 0 0 0 0 0 0 0 0 0 0 0
1 5 5 6 1 1 0 ff 0 0 1 0 ff
4 8 8 6 ff 0 0 0 ff 0 1 0 1
4 7 7 8 0 0 0 0 0 0 1 0 1
Si aplicamos la inversa de los filtros a cada pixel tenemos (en decimal), que
sería la imagen original:
0 0 0 0 0 0 0 0 0 0 0 0
5 5 6 6 6 6 5 6 6 6 6 5
13 13 12 12 13 12 12 12 12 13 12 13
20 20 20 20 20 20 20 20 20 21 20 21